from glob import glob
import numpy as np
import pandas as pd
import earthaccess
import geopandas as gpd
import requests as re
import s3fs
import h5py
from os import path
from datetime import datetime
from shapely.ops import orient
from shapely.geometry import Polygon, MultiPolygon
import matplotlib.pyplot as plt
from shapely.geometry import box
import dask.dataframe as dd
from harmony import BBox,Client, Collection, Request, LinkTypeBIOSPACE25 Workshop:
Harnessing analysis tools for biodiversity applications using field, airborne, and orbital remote sensing data from NASA’s BioSCAPE campaign
Michele Thornton, Rupesh Shrestha, Erin Hestir, Adam Wilson, Jasper Slingsby, Anabelle Cardoso
Date: February 12, 2025, Frascati (Rome), Italy

Exploring and Visualizing BioSCape LVIS Data
Overview
BioSCape, the Biodiversity Survey of the Cape, is NASA’s first biodiversity-focused airborne and field campaign that was conducted in South Africa in 2023. BioSCape’s primary objective is to study the structure, function, and composition of the region’s ecosystems, and how and why they are changing.
BioSCape’s airborne dataset is unprecedented, with AVIRIS-NG, PRISM, and HyTES imaging spectrometers capturing spectral data across the UV, visible and infrared at high resolution and LVIS acquiring coincident full-waveform lidar. BioSCape’s field dataset is equally impressive, with 18 PI-led projects collecting data ranging from the diversity and phylogeny of plants, kelp and phytoplankton, eDNA, landscape acoustics, plant traits, blue carbon accounting, and more
This tutorial will demonstrate accessing and visualizing Land, Vegetation, and Ice Sensor (LVIS) data available on the BioSCape SMCE. LVIS is an airborne, wide-swath imaging full-waveform laser altimeter. LVIS collects in a 1064 nm-wavelength (near infrared) range with 3 detectors mounted in an airborne platform, flown typically ~10 km above the ground producing a data swath of 2km wide with 7-10 m footprints. More information about the LVIS instrument is here.
The LVIS instrument has been flown above several regions of the world since 1998. The LVIS flights were collected for the BioSCAPE campaigns from 01 Oct 2023 through 30 Nov 2023.
There are three LVIS BioSCape data products currently available and archived at NSIDC DAAC
| Dataset | Dataset DOI |
|---|---|
| LVIS L1A Geotagged Images V001 | 10.5067/NE5KKKBAQG44 |
| LVIS Facility L1B Geolocated Return Energy Waveforms V001 | 10.5067/XQJ8PN8FTIDG |
| LVIS Facility L2 Geolocated Surface Elevation and Canopy Height Product V001 | 10.5067/VP7J20HJQISD |
For this tutorial, we’ll examine the LVIS L2 Geolocated Surface Elevation and Canopy Height Product V001
- Citation: Blair, J. B. & Hofton, M. (2020). LVIS Facility L2 Geolocated Surface Elevation and Canopy Height Product, Version 1 [Data Set]. Boulder, Colorado USA. NASA National Snow and Ice Data Center Distributed Active Archive Center. https://doi.org/10.5067/VP7J20HJQISD.
- User Guide LVIS Facility L2 Geolocated Surface Elevation and Canopy Height Product, Version1
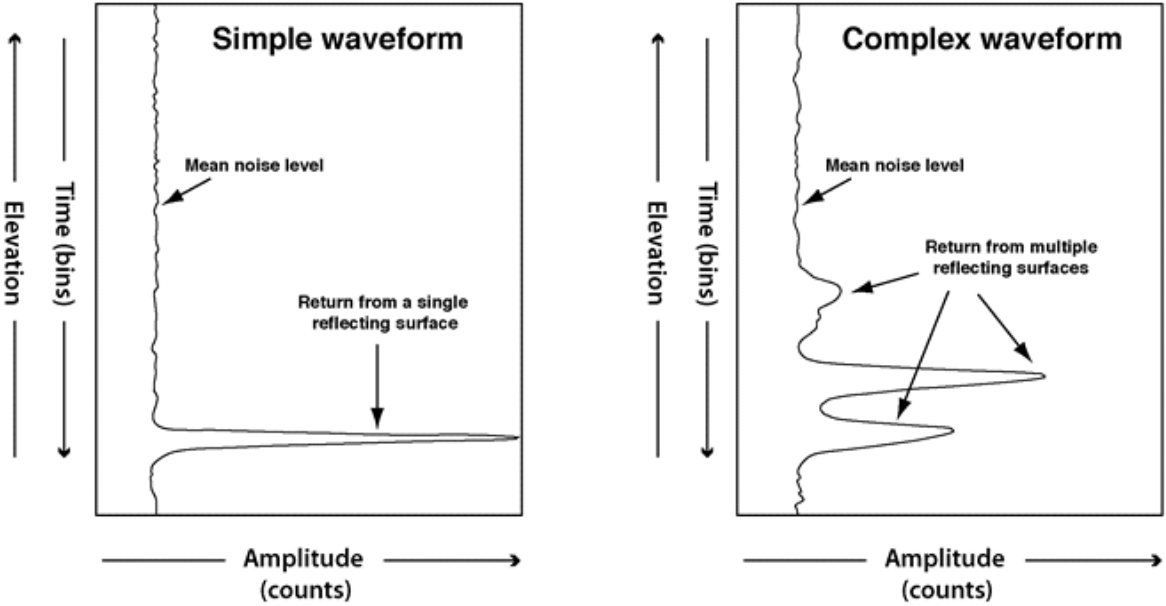 Figure: Sample LVIS product waveforms illustrating possible distributions of reflected light (Blair et al., 2020)
Figure: Sample LVIS product waveforms illustrating possible distributions of reflected light (Blair et al., 2020)
# esri background basemap for maps
xyz = "https://server.arcgisonline.com/ArcGIS/rest/services/World_Imagery/MapServer/tile/{z}/{y}/{x}"
attr = "ESRI"Authentication
We recommend authenticating your Earthdata Login (EDL) information using the earthaccess python library as follows:
# works if the EDL login already been persisted to a netrc
try:
auth = earthaccess.login(strategy="netrc")
except FileNotFoundError:
# ask for EDL credentials and persist them in a .netrc file
auth = earthaccess.login(strategy="interactive", persist=True)Structure LVIS L1B Geolocated Waveform
First, let’s find out how many L1B files from the BioSCape Campaign are published on NASA Earthdata.
doi="10.5067/XQJ8PN8FTIDG" # LVIS L1B doi
query = earthaccess.DataGranules().doi(doi)
query.params['campaign'] = 'bioscape'
l1b = query.get_all()
print(f'Granules found: {len(l1b)}')Granules found: 2328There are 2328 granules LVIS L1B product found for the time period. Let’s see if they are hosted on Earthdata cloud or not, by printing a summary of one granule
def get_granule_index(granules, dts):
"""returns granule index matching timestamp"""
for index, val in enumerate(l1b):
if f'_{dts}' in val.data_links()[0]:
return index
# index of granule with R2404_041222 datetime stamp
i = get_granule_index(l1b, 'R2404_041222')
l1b[i]
As we see above, the LVIS files are not cloud-hosted yet. They have to be downloaded locally and use them. We will go ahead and use earthaccess python module to get the file directly and save it to the downloads directory.
# download files
downloaded_files = earthaccess.download(l1b[i], local_path="downloads")Now, we go ahead and open a file to look at its structure.
l1b_i= f'downloads/{path.basename(l1b[i].data_links()[0])}'
with h5py.File(l1b_i) as hf:
for v in list(hf.keys()):
if v != "ancillary_data":
print(f"- {v} : {hf[v].attrs['description'][0].decode('utf-8')}")- AZIMUTH : Azimuth angle of laser beam
- INCIDENTANGLE : Off-nadir incident angle of laser beam
- LAT0 : Latitude of the highest sample of the return waveform (degrees north)
- LAT1215 : Latitude of the lowest sample of the return waveform (degrees north)
- LFID : LVIS file identification. Together with 'LVIS shotnumber' these are a unique identifier for every LVIS laser shot. Format is XXYYYYYZZZ where XX identifies instrument version, YYYYY is the Modified Julian Date of the flight departure day, ZZZ represents file number.
- LON0 : Longitude of the highest sample of the return waveform (degrees east)
- LON1215 : Longitude of the lowest sample of the return waveform (degrees east)
- RANGE : Distance along laser path from the instrument to the ground
- RXWAVE : Returned waveform (1216 samples long)
- SHOTNUMBER : Laser shot number assigned during collection. Together with 'LVIS LFID' provides a unique identifier to every LVIS laser shot.
- SIGMEAN : Signal mean noise level, calculated in-flight
- TIME : UTC decimal seconds of the day
- TXWAVE : Transmitted waveform (128 samples long)
- Z0 : Elevation of the highest sample of the waveform with respect to the reference ellipsoid
- Z1215 : Elevation of the lowest sample of the waveform with respect to the reference ellipsoidwith h5py.File(l1b_i) as hf:
l_lat = hf['LAT1215'][:]
l_lon = hf['LON1215'][:]
l_range = hf['Z1215'][:] # ground elevation
shot = hf['SHOTNUMBER'][:] # ground elevation
geo_arr = list(zip(shot, l_range,l_lat,l_lon))
l1b_df = pd.DataFrame(geo_arr, columns=["shot_number", "elevation", "lat", "lon"])
l1b_df| shot_number | elevation | lat | lon | |
|---|---|---|---|---|
| 0 | 53962803 | -11.535183 | -33.984506 | 23.578263 |
| 1 | 53962804 | -10.865241 | -33.984441 | 23.578345 |
| 2 | 53962805 | -11.777588 | -33.984439 | 23.578265 |
| 3 | 53962806 | -11.115836 | -33.984374 | 23.578346 |
| 4 | 53962807 | -10.604997 | -33.984372 | 23.578266 |
| ... | ... | ... | ... | ... |
| 349995 | 54314213 | 127.315796 | -33.982573 | 23.384180 |
| 349996 | 54314214 | 125.984406 | -33.982510 | 23.384260 |
| 349997 | 54314215 | 131.266342 | -33.982505 | 23.384181 |
| 349998 | 54314216 | 129.814392 | -33.982441 | 23.384262 |
| 349999 | 54314217 | 132.638367 | -33.982437 | 23.384183 |
350000 rows × 4 columns
l1b_gdf = gpd.GeoDataFrame(l1b_df[['shot_number', 'elevation']], crs="EPSG:4326",
geometry=gpd.points_from_xy(l1b_df.lon,
l1b_df.lat))
m = l1b_gdf.sample(frac=0.01).explore("elevation", cmap = "plasma", tiles=xyz, attr=attr)
# plot a single shot as red
i = np.where(shot==54132593)[0][0]
l1b_gdf.iloc[[i]].explore(m=m, marker_type="marker")
mMake this Notebook Trusted to load map: File -> Trust Notebook
with h5py.File(l1b_i) as hf:
rxwaveform = hf['RXWAVE'][i, :] # waveform
elev_1215 = hf['Z1215'][i] # elevation ground
elev_0 = hf['Z0'][i] # elevation top
c = len(rxwaveform) #
elev = np.linspace(elev_1215, elev_0, num=c)
# plot
plt.rcParams["figure.figsize"] = (3,10)
plt.xlabel("rxwaveform (counts)")
plt.ylabel("elevation (m)")
plt.plot(rxwaveform, elev, linestyle='--', marker='.',)
plt.show()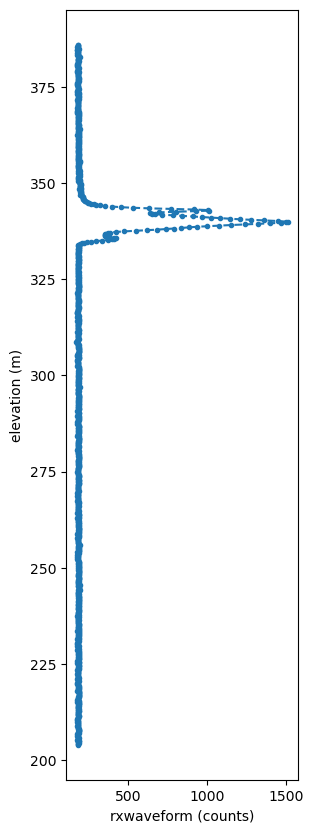
Structure of LVIS L2 Canopy Height Product
First, let’s search how many L2 files are there for the BioSCape campaign dates.
doi="10.5067/VP7J20HJQISD" # LVIS L2 doi
query = earthaccess.DataGranules().doi(doi)
query.params['campaign'] = 'bioscape'
l2 = query.get_all()
print(f'Granules found: {len(l2)}')Granules found: 2328There are 2328 granules LVIS L2 product found for the time period. Let’s see if they are hosted on Earthdata cloud or not, by printing a summary of the first granule
# index of granule with R2404_041222 datetime stamp
i = get_granule_index(l2, 'R2404_041222')
l2[i]
As we see above, the LVIS files are not cloud-hosted yet. They have to be downloaded locally and use them. We will go ahead and use earthaccess python module to get the file directly and save it to the downloads directory.
# download files
downloaded_files = earthaccess.download(l2[i], local_path="downloads")Now, we’ll go ahead and open a file to look at it’s structure.
l2_i = f'downloads/{path.basename(l2[i].data_links()[0])}'
with open(l2_i, 'r') as f:
# print first 15 rows
head = [next(f) for _ in range(15)]
print(head)["# Level2 (v2.0.5) data set collected by NASA's Land, Vegetation and Ice Sensor (LVIS) Facility in October-November 2023 as part of NASA's BioSCape Field Campaign. This file contains elevation,\n", "# height and surface structure metrics derived from LVIS's geolocated laser return waveform. The corresponding spatially geolocated laser return waveforms are contained in the Level 1B data set.\n", '# For supporting information please visit https://lvis.gsfc.nasa.gov/Data/Maps/SouthAfrica2023Map.html. LVIS-targeted data collections occurred at flight altitudes of ~7 km above the surface from\n', '# the NASA G-V, however data collections also occurred at lower altitudes. The "Range" parameter can be used to determine flight altitude. Note: Two alternate ground elevations options are provided\n', '# in order to provide flexibility for local site conditions; if selected for use, adjust the values of the RH parameters accordingly. Please consult the User Guide for further information. The data\n', '# have had limited quality assurance checking, although obvious lower quality data have been removed, e.g., clouds and cloud-obscured returns. We highly recommend that end users contact us about\n', '# any idiosyncrasies or unexpected results.\n', '#\n', '# LFID SHOTNUMBER TIME GLON GLAT ZG ZG_ALT1 ZG_ALT2 HLON HLAT ZH TLON TLAT ZT RH10 RH15 RH20 RH25 RH30 RH35 RH40 RH45 RH50 RH55 RH60 RH65 RH70 RH75 RH80 RH85 RH90 RH95 RH96 RH97 RH98 RH99 RH100 AZIMUTH INCIDENTANGLE RANGE COMPLEXITY SENSITIVITY CHANNEL_ZT CHANNEL_ZG CHANNEL_RH\n', '1960249451 53962803 41222.74027 23.578263 -33.984515 30.37 30.37 30.37 23.578263 -33.984515 30.37 23.578263 -33.984516 32.85 -1.05 -0.86 -0.71 -0.60 -0.49 -0.41 -0.30 -0.22 -0.15 -0.07 0.00 0.07 0.19 0.26 0.34 0.45 0.60 0.82 0.90 0.97 1.12 1.46 2.47 3.93 1.362 6641.88 0.101 0.989 1 1 1\n', '1960249451 53962804 41222.74052 23.578344 -33.984450 30.11 30.11 30.11 23.578344 -33.984450 30.11 23.578343 -33.984451 33.29 -0.90 -0.71 -0.56 -0.45 -0.34 -0.26 -0.19 -0.11 -0.04 0.04 0.11 0.19 0.30 0.37 0.49 0.64 0.82 1.12 1.20 1.31 1.46 1.72 3.18 6.35 1.429 6642.63 0.117 0.989 1 1 1\n', '1960249451 53962805 41222.74077 23.578264 -33.984448 29.72 29.72 29.72 23.578264 -33.984448 29.72 23.578264 -33.984448 31.52 -0.86 -0.67 -0.56 -0.45 -0.37 -0.30 -0.22 -0.19 -0.11 -0.07 0.00 0.04 0.11 0.15 0.22 0.30 0.41 0.56 0.60 0.67 0.79 1.09 1.80 3.83 1.426 6641.88 0.145 0.978 1 1 1\n', '1960249451 53962806 41222.74102 23.578345 -33.984384 30.27 30.27 30.27 23.578345 -33.984384 30.27 23.578345 -33.984384 31.95 -0.82 -0.64 -0.49 -0.41 -0.30 -0.22 -0.19 -0.11 -0.04 0.04 0.11 0.15 0.22 0.30 0.41 0.52 0.64 0.82 0.90 0.94 1.01 1.16 1.69 6.16 1.493 6642.19 0.141 0.989 1 1 1\n', '1960249451 53962807 41222.74127 23.578266 -33.984381 29.95 29.95 29.95 23.578266 -33.984384 39.69 23.578266 -33.984384 41.53 -0.75 -0.56 -0.45 -0.34 -0.26 -0.19 -0.11 -0.04 -0.00 0.07 0.15 0.22 0.34 0.45 0.90 8.16 9.14 9.89 10.04 10.22 10.45 10.82 11.57 3.75 1.490 6642.63 0.496 0.982 1 1 1\n', '1960249451 53962808 41222.74152 23.578347 -33.984317 30.02 30.02 30.02 23.578346 -33.984319 39.90 23.578346 -33.984320 42.53 -0.34 -0.15 0.04 0.22 0.49 6.03 8.54 8.95 9.18 9.36 9.55 9.70 9.81 9.96 10.11 10.26 10.49 10.94 11.12 11.31 11.50 11.80 12.51 5.98 1.557 6641.74 0.401 0.990 1 1 1\n']LVIS L2A files have a number of lines as header as shown above. Let’s define a python function to read the number of header rows.
def get_line_number(filename):
"""find number of header rows in LVIS L2A"""
count = 0
with open(filename, 'r') as f:
for line in f:
if line.startswith('#'):
count = count + 1
columns = line[1:].split()
else:
return count, columnsh_no, col_names = get_line_number(l2_i)
with open(l2_i, 'r') as f:
l2a_df = pd.read_csv(f, skiprows=h_no, header=None, engine='python', sep=r'\s+')
l2a_df.columns = col_names
l2a_df| LFID | SHOTNUMBER | TIME | GLON | GLAT | ZG | ZG_ALT1 | ZG_ALT2 | HLON | HLAT | ... | RH99 | RH100 | AZIMUTH | INCIDENTANGLE | RANGE | COMPLEXITY | SENSITIVITY | CHANNEL_ZT | CHANNEL_ZG | CHANNEL_RH | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1960249451 | 53962803 | 41222.74027 | 23.578263 | -33.984515 | 30.37 | 30.37 | 30.37 | 23.578263 | -33.984515 | ... | 1.46 | 2.47 | 3.93 | 1.362 | 6641.88 | 0.101 | 0.989 | 1 | 1 | 1 |
| 1 | 1960249451 | 53962804 | 41222.74052 | 23.578344 | -33.984450 | 30.11 | 30.11 | 30.11 | 23.578344 | -33.984450 | ... | 1.72 | 3.18 | 6.35 | 1.429 | 6642.63 | 0.117 | 0.989 | 1 | 1 | 1 |
| 2 | 1960249451 | 53962805 | 41222.74077 | 23.578264 | -33.984448 | 29.72 | 29.72 | 29.72 | 23.578264 | -33.984448 | ... | 1.09 | 1.80 | 3.83 | 1.426 | 6641.88 | 0.145 | 0.978 | 1 | 1 | 1 |
| 3 | 1960249451 | 53962806 | 41222.74102 | 23.578345 | -33.984384 | 30.27 | 30.27 | 30.27 | 23.578345 | -33.984384 | ... | 1.16 | 1.69 | 6.16 | 1.493 | 6642.19 | 0.141 | 0.989 | 1 | 1 | 1 |
| 4 | 1960249451 | 53962807 | 41222.74127 | 23.578266 | -33.984381 | 29.95 | 29.95 | 29.95 | 23.578266 | -33.984384 | ... | 10.82 | 11.57 | 3.75 | 1.490 | 6642.63 | 0.496 | 0.982 | 1 | 1 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 349995 | 1960249454 | 54314213 | 41310.59375 | 23.384180 | -33.982544 | 167.46 | 167.46 | 167.46 | 23.384180 | -33.982535 | ... | 15.95 | 17.18 | 180.56 | 4.637 | 6525.42 | 0.550 | 0.997 | 1 | 1 | 1 |
| 349996 | 1960249454 | 54314214 | 41310.59400 | 23.384260 | -33.982480 | 168.45 | 168.45 | 168.45 | 23.384260 | -33.982470 | ... | 12.44 | 14.60 | 179.75 | 4.575 | 6524.37 | 0.589 | 0.993 | 1 | 1 | 1 |
| 349997 | 1960249454 | 54314215 | 41310.59425 | 23.384182 | -33.982473 | 175.07 | 175.07 | 175.07 | 23.384182 | -33.982469 | ... | 8.63 | 10.01 | 180.54 | 4.573 | 6520.03 | 0.498 | 0.994 | 1 | 1 | 1 |
| 349998 | 1960249454 | 54314216 | 41310.59450 | 23.384262 | -33.982410 | 174.26 | 174.26 | 169.81 | 23.384261 | -33.982406 | ... | 7.40 | 8.74 | 179.72 | 4.511 | 6521.22 | 0.472 | 0.993 | 1 | 1 | 1 |
| 349999 | 1960249454 | 54314217 | 41310.59475 | 23.384184 | -33.982406 | 177.49 | 177.49 | 177.49 | 23.384184 | -33.982402 | ... | 8.89 | 9.97 | 180.52 | 4.509 | 6517.63 | 0.557 | 0.995 | 1 | 1 | 1 |
350000 rows × 45 columns
Let’s print LVIS L2 variable names.
l2a_df.columns.valuesarray(['LFID', 'SHOTNUMBER', 'TIME', 'GLON', 'GLAT', 'ZG', 'ZG_ALT1',
'ZG_ALT2', 'HLON', 'HLAT', 'ZH', 'TLON', 'TLAT', 'ZT', 'RH10',
'RH15', 'RH20', 'RH25', 'RH30', 'RH35', 'RH40', 'RH45', 'RH50',
'RH55', 'RH60', 'RH65', 'RH70', 'RH75', 'RH80', 'RH85', 'RH90',
'RH95', 'RH96', 'RH97', 'RH98', 'RH99', 'RH100', 'AZIMUTH',
'INCIDENTANGLE', 'RANGE', 'COMPLEXITY', 'SENSITIVITY',
'CHANNEL_ZT', 'CHANNEL_ZG', 'CHANNEL_RH'], dtype=object)Key variables: - The GLAT and GLON variables provide coordinates of the lowest detected mode within the LVIS waveform. - The RHXX variables provide height above the lowest detected mode at which XX percentile of the waveform energy. - RANGE provides the distance from the instrument to the ground. - SENSITIVITY provides sensitivity metric for the return waveform. - ZG,ZG_ALT1, ZG_ALT2: Mean elevation of the lowest detected mode using alternate 1/2 mode detection settings. The alternative ZG to use to adjust the RH parameters for local site conditions.
More information about the variables are provided in the user guide.
Let’s select the particular shot we are interested in.
l2a_shot_df = l2a_df[l2a_df['SHOTNUMBER'] == 54132593]
l2a_shot_df| LFID | SHOTNUMBER | TIME | GLON | GLAT | ZG | ZG_ALT1 | ZG_ALT2 | HLON | HLAT | ... | RH99 | RH100 | AZIMUTH | INCIDENTANGLE | RANGE | COMPLEXITY | SENSITIVITY | CHANNEL_ZT | CHANNEL_ZG | CHANNEL_RH | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 168896 | 1960249452 | 54132593 | 41265.18824 | 23.484723 | -33.980404 | 247.05 | 247.05 | 247.05 | 23.484723 | -33.980405 | ... | 7.83 | 8.76 | 7.01 | 1.631 | 6427.33 | 0.32 | 0.994 | 1 | 1 | 1 |
1 rows × 45 columns
Now, we can plot the RH metrics with elevation.
elev_zg = l2a_shot_df.ZG.values[0]
elev_zh = l2a_shot_df.ZH.values[0]
rh40 = l2a_shot_df.RH40.values[0]
rh80 = l2a_shot_df.RH80.values[0]
rh100 = l2a_shot_df.RH100.values[0]
rh = l2a_shot_df.filter(like ='RH').drop('CHANNEL_RH', axis=1).values.tolist()[0]
# plotting
plt.rcParams["figure.figsize"] = (5,7)
rh_vals = l2a_shot_df.filter(like = 'RH').columns[:-1].str.strip('RH').astype(int).tolist()
fig, ax1 = plt.subplots()
ax1.plot(rh_vals, elev_zg+rh, alpha=0.3, marker='o', color='black', label='RH metrics' )
ax1.axhline(y=elev_zg+rh40, color='g', linestyle='dotted', linewidth=2, label='RH40')
ax1.axhline(y=elev_zg+rh80, color='g', linestyle='-.', linewidth=2, label='RH80')
ax1.axhline(y=elev_zg+rh100, color='g', linestyle='--', linewidth=3, label='RH100')
ax1.set_xlabel("Percentile of waveform energy (%)")
ax1.set_ylabel("elevation (meters)")
ax1.legend(loc="lower right")
plt.show()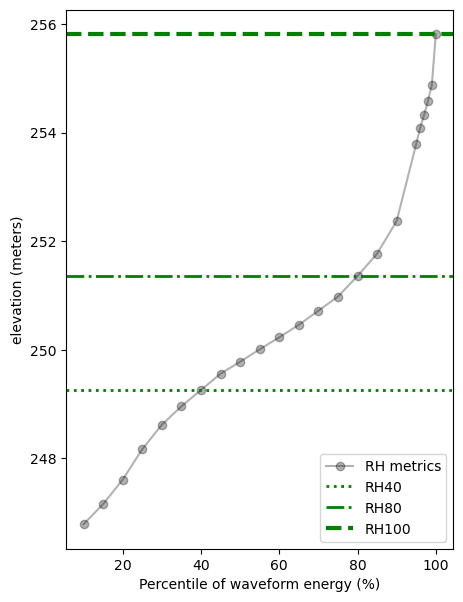
Plot LVIS Bioscape Campaigns
Lets first define two functions that we can use to plot the search results above over a basemap.
def convert_umm_geometry(gpoly):
"""converts UMM geometry to multipolygons"""
multipolygons = []
for gl in gpoly:
ltln = gl["Boundary"]["Points"]
points = [(p["Longitude"], p["Latitude"]) for p in ltln]
multipolygons.append(Polygon(points))
return MultiPolygon(multipolygons)
def convert_list_gdf(datag):
"""converts List[] to geopandas dataframe"""
# create pandas dataframe from json
df = pd.json_normalize([vars(granule)['render_dict'] for granule in datag])
# keep only last string of the column names
df.columns=df.columns.str.split('.').str[-1]
# convert polygons to multipolygonal geometry
df["geometry"] = df["GPolygons"].apply(convert_umm_geometry)
# return geopandas dataframe
return gpd.GeoDataFrame(df, geometry="geometry", crs="EPSG:4326")Now, we will convert the JSON return from the earthaccess granule search into a geopandas dataframe so we could plot over an ESRI basemap.
gdf = convert_list_gdf(l2)
#plot
gdf[['BeginningDateTime','geometry']].explore(tiles=xyz, attr=attr)Make this Notebook Trusted to load map: File -> Trust Notebook
The above shows the flight lines of all LVIS collection during the BioSCape campaign in 2023.
Search LVIS L2A granules over a study area
The study area is Brackenburn Private Nature Reserve.
poly_f = "assets/brackenburn.json"
poly = gpd.read_file(poly_f)
poly.explore(tiles=xyz, attr=attr, style_kwds={'color':'red', 'fill':False})Make this Notebook Trusted to load map: File -> Trust Notebook
Let’s search for LVIS L2A granules that are within the bounds of the study area.
poly.geometry = poly.geometry.apply(orient, args=(1,))
# simplifying the polygon to bypass the coordinates
# limit of the CMR with a tolerance of .005 degrees
xy = poly.geometry.simplify(0.005).get_coordinates()
l2_poly = earthaccess.search_data(
count=-1, # needed to retrieve all granules
doi="10.5067/VP7J20HJQISD", # LVIS L2A doi
temporal=("2023-10-01", "2023-11-30"), # Bioscape campaign dates
polygon=list(zip(xy.x, xy.y))
)
print(f'Granules found: {len(l2_poly)}')Granules found: 9Let’s plot these flight lines over a basemap.
gdf = convert_list_gdf(l2_poly)
m = gdf[['BeginningDateTime','geometry']].explore(tiles=xyz, attr=attr,
style_kwds={'fillOpacity':0.1})
mMake this Notebook Trusted to load map: File -> Trust Notebook
Download L2 granules
In the above section, we retrieved the overlapping granules using the earthaccess module, which we will also use to download the files.
downloaded_files = earthaccess.download(l2_poly, local_path="downloads")Earthaccess download uses a parallel downloading feature so all the files are downloaded efficiently. It also avoids duplicated downloads if a file has already been downloaded previously to the local path.
Read LVIS L2A Files
Now, we can read the LVIS L2A files into a pandas dataframe.
# get header rows and column names
h_no, col_names = get_line_number(downloaded_files[0])
# read the LVIS L2A files
ddf = dd.read_csv(downloaded_files, skiprows=h_no, names=col_names,
header=None, sep=r'\s+')
# dask to pandas dataframe
df = ddf.compute()
# converting to geopandas
lvis_l2a_gdf = gpd.GeoDataFrame(df,
geometry=gpd.points_from_xy(df.GLON,
df.GLAT),
crs="EPSG:4326")
# clipping LVIS by polygon
lvis_l2a_gdf = gpd.sjoin(lvis_l2a_gdf, poly, predicate='within')Height of Top Canopy
Let’s plot RH100 (height of top canopy) values in a map.
lvis_l2a_gdf[['RH100', 'geometry']].sample(frac=0.1, random_state=1).explore(
"RH100", cmap = "YlGn", tiles=xyz, attr=attr, alpha=0.5, radius=10, legend=True)Make this Notebook Trusted to load map: File -> Trust Notebook
Relative Height Distribution
We can generate a plot of RH metrics to check if the vegetation height across the percentile of waveform energy indicates the same.
fig, ax = plt.subplots(figsize=(7, 8))
plot_df = lvis_l2a_gdf.sample(frac=0.1, random_state=1).filter(like='RH').drop('CHANNEL_RH', axis=1).T
plot_df.index = plot_df.index.str.strip('RH').astype(int)
std_df = plot_df.std(axis=1)
median_df = plot_df.median(axis=1)
median_df.plot(ax=ax, alpha=0.5, style='o-')
ax.fill_between(plot_df.index, median_df - std_df, median_df + std_df, alpha=0.1)
ax.set_xlabel("Percentile of waveform energy (%)")
ax.set_ylabel("Height (m)")
plt.show()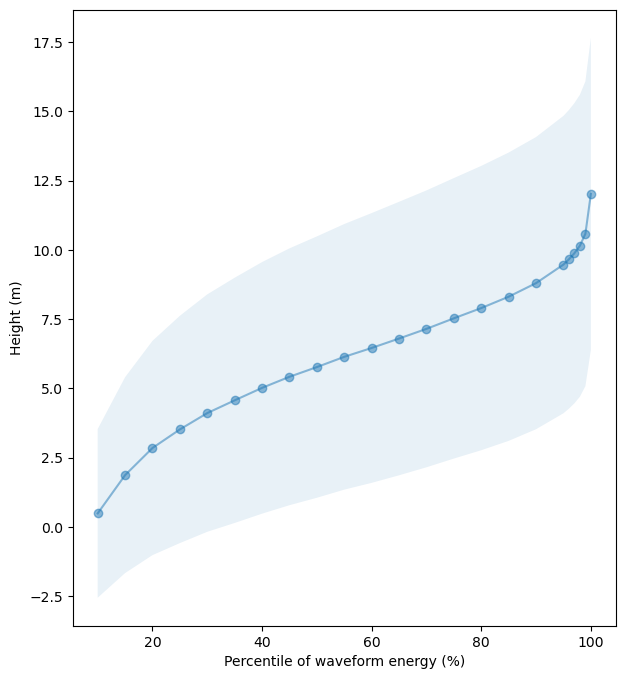
# exporting
# lvis_l2a_gdf.geometry.to_file('lvis2.geojson', driver="GeoJSON")
# lvis_l2a_gdf.to_csv('lvis.csv')GEDI L2A Canopy Height Metrics
This section of the tutorial will demonstrate how to directly access and subset the GEDI L2A canopy height metrics using NASA’s Harmony Services and compute a summary of aboveground biomass density for a forest reserve. The Harmony API allows seamless access and production of analysis-ready Earth observation data across different DAACs by enabling cloud-based spatial, temporal, and variable subsetting and data conversions. The GEDI datasets are available from the Harmony Trajectory Subsetter API(id =S2836723123-XYZ_PROV).
We will use NASA’s Harmony Services to retrieve the GEDI L2A dataset and canopy heights (RH100) for the burned and unburned plots . The Harmony API allows access to selected variables for the dataset within the spatial-temporal bounds without having to download the whole data file.
Dataset
The GEDI Level 2A Geolocated Elevation and Height Metrics product GEDI02_A provides waveform interpretation and extracted products from eachreceived waveform, including ground elevation, canopy top height, and relative height (RH) metrics. GEDI datasets are available for the period starting 2019-04-17 and covers 52 N to 52 S latitudes. GEDI L2A data files are natively in HDF5 format.
Authentication
NASA Harmony API requires NASA Earthdata Login (EDL). You can use the earthaccess Python library to set up authentication. Alternatively, you can also login to harmony_client directly by passing EDL authentication as the following in the Jupyter Notebook itself:
harmony_client = Client(auth=("your EDL username", "your EDL password"))Create Harmony Client Object
First, we create a Harmony Client object. If you are passing the EDL authentication, please do as shown above with the auth parameter.
harmony_client = Client()concept_l2a = earthaccess.search_datasets(doi ='10.5067/GEDI/GEDI02_A.002')[0].concept_id()
concept_l2a'C1908348134-LPDAAC_ECS'Retrieve Concept ID
Now, let’s retrieve the Concept ID of the GEDI L2A dataset. The Concept ID is NASA Earthdata’s unique ID for its dataset.
def get_concept_id(doi):
"""get concept id from DOI using earthaccess"""
col = earthaccess.search_datasets(doi=doi)
for ds in col:
# check if Harmony trajectory subsets exists
if 'S2836723123-XYZ_PROV' in ds.services().keys():
return(ds.concept_id())
concept_l2a = get_concept_id('10.5067/GEDI/GEDI02_A.002')
concept_l2a'C2142771958-LPCLOUD'Define Request Parameters
Let’s create a Harmony Collection object with the concept_id retrieved above. We will also define the GEDI L2A RH variables and temporal range.
# harmony collection
collection_l2a = Collection(id=concept_l2a)
def create_var_names(variables):
# gedi beams
beams = ['BEAM0000', 'BEAM0001', 'BEAM0010', 'BEAM0011', 'BEAM0101', 'BEAM0110', 'BEAM1000', 'BEAM1011']
# combine variables and beam names
return [f'/{b}/{v}' for b in beams for v in variables]
# gedi variables
variables_l2a = create_var_names(['rh', 'quality_flag', 'land_cover_data/pft_class'])
# time range
temporal_range = {'start': datetime(2019, 4, 17),
'stop': datetime(2023, 3, 31)}Create and Submit Harmony Request
Now, we can create a Harmony request with variables, temporal range, and bounding box and submit the request using the Harmony client object. We will use the download_all method, which uses a multithreaded downloader and returns a concurrent future. Futures are asynchronous and let us use the downloaded file as soon as the download is complete while other files are still being downloaded.
def submit_harmony(collection, variables):
"""submit harmony request"""
request = Request(collection=collection,
variables=variables,
temporal=temporal_range,
shape=poly_f,
ignore_errors=True)
# submit harmony request, will return job id
subset_job_id = harmony_client.submit(request)
return harmony_client.result_urls(subset_job_id, show_progress=True,
link_type=LinkType.s3)
results = submit_harmony(collection_l2a, variables_l2a)A temporary S3 Credentials is needed for read-only, same-region (us-west-2), direct access to S3 objects on the Earthdata cloud. We will use the credentials from the harmony_client.
s3credentials = harmony_client.aws_credentials()We will pass S3 credentials to S3Fs class S3FileSystem.
fs_s3 = s3fs.S3FileSystem(anon=False,
key=s3credentials['aws_access_key_id'],
secret=s3credentials['aws_secret_access_key'],
token=s3credentials['aws_session_token'])Read Subset files
First, we will define a python function to read the GEDI variables, which are organized in a hierarchical way.
def read_gedi_vars(beam):
"""reads through gedi variable hierarchy"""
col_names = []
col_val = []
# read all variables
for key, value in beam.items():
# check if the item is a group
if isinstance(value, h5py.Group):
# looping through subgroups
for key2, value2 in value.items():
col_names.append(key2)
col_val.append(value2[:].tolist())
else:
col_names.append(key)
col_val.append(value[:].tolist())
return col_names, col_valLet’s direct access the subsetted h5 files and retrieve its values into the pandas dataframe.
# define an empty pandas dataframe
subset_df = pd.DataFrame()
# loop through the Harmony results
for s3_url in results:
print(s3_url)
with fs_s3.open(s3_url, mode='rb') as fh:
with h5py.File(fh) as l2a_in:
for v in list(l2a_in.keys()):
if v.startswith('BEAM'):
c_n, c_v = read_gedi_vars(l2a_in[v])
# Appending to the subset_df dataframe
subset_df = pd.concat([subset_df,
pd.DataFrame(map(list, zip(*c_v)),
columns=c_n)]) [ Processing: 80% ] |######################################## | [\]
Job is running with errors.
[ Processing: 100% ] |###################################################| [|]s3://harmony-prod-staging/public/9edfdbc6-4326-43f5-b9e0-52349b9cbf82/89838542/GEDI02_A_2019187095905_O03192_04_T04838_02_003_01_V002_subsetted.h5
s3://harmony-prod-staging/public/9edfdbc6-4326-43f5-b9e0-52349b9cbf82/89838555/GEDI02_A_2022303102350_O21984_04_T08954_02_003_02_V002_subsetted.h5
s3://harmony-prod-staging/public/9edfdbc6-4326-43f5-b9e0-52349b9cbf82/89838546/GEDI02_A_2020249085848_O09813_04_T10530_02_003_02_V002_subsetted.h5
s3://harmony-prod-staging/public/9edfdbc6-4326-43f5-b9e0-52349b9cbf82/89838545/GEDI02_A_2020096211823_O07449_04_T01992_02_003_01_V002_subsetted.h5
s3://harmony-prod-staging/public/9edfdbc6-4326-43f5-b9e0-52349b9cbf82/89838544/GEDI02_A_2020029234554_O06412_04_T04838_02_003_01_V002_subsetted.h5
s3://harmony-prod-staging/public/9edfdbc6-4326-43f5-b9e0-52349b9cbf82/89838543/GEDI02_A_2019295150627_O04871_04_T01992_02_003_01_V002_subsetted.h5
s3://harmony-prod-staging/public/9edfdbc6-4326-43f5-b9e0-52349b9cbf82/89838548/GEDI02_A_2021076044301_O12802_04_T10530_02_003_02_V002_subsetted.h5
s3://harmony-prod-staging/public/9edfdbc6-4326-43f5-b9e0-52349b9cbf82/89838541/GEDI02_A_2019167025613_O02877_01_T05165_02_003_01_V002_subsetted.h5
s3://harmony-prod-staging/public/9edfdbc6-4326-43f5-b9e0-52349b9cbf82/89838558/GEDI02_A_2023043015154_O23607_01_T02319_02_003_02_V002_subsetted.h5
s3://harmony-prod-staging/public/9edfdbc6-4326-43f5-b9e0-52349b9cbf82/89838557/GEDI02_A_2022347020044_O22661_01_T05165_02_003_02_V002_subsetted.h5
s3://harmony-prod-staging/public/9edfdbc6-4326-43f5-b9e0-52349b9cbf82/89838553/GEDI02_A_2022269000101_O21450_04_T04838_02_003_02_V002_subsetted.h5
s3://harmony-prod-staging/public/9edfdbc6-4326-43f5-b9e0-52349b9cbf82/89838540/GEDI02_A_2019120211737_O02159_01_T02319_02_003_01_V002_subsetted.h5
s3://harmony-prod-staging/public/9edfdbc6-4326-43f5-b9e0-52349b9cbf82/89838554/GEDI02_A_2022278051640_O21593_01_T10857_02_003_02_V002_subsetted.h5
s3://harmony-prod-staging/public/9edfdbc6-4326-43f5-b9e0-52349b9cbf82/89838556/GEDI02_A_2022333221837_O22457_04_T10530_02_003_02_V002_subsetted.h5
s3://harmony-prod-staging/public/9edfdbc6-4326-43f5-b9e0-52349b9cbf82/89838551/GEDI02_A_2022052222802_O18099_01_T10857_02_003_04_V002_subsetted.h5Let’s remove the duplicate columns, if any, and print the first two rows of the pandas dataframe.
# remove duplicate columns
subset_df = subset_df.loc[:,~subset_df.columns.duplicated()].copy()
subset_df.head(2)| delta_time | lat_lowestmode_a1 | lon_lowestmode_a1 | pft_class | lat_lowestmode | lon_lowestmode | quality_flag | rh | |
|---|---|---|---|---|---|---|---|---|
| 0 | 4.764720e+07 | -33.980864 | 23.475097 | 2 | -33.980862 | 23.475095 | 1 | [-3.4000000953674316, -1.8300000429153442, -0.... |
| 1 | 4.764720e+07 | -33.981219 | 23.475540 | 2 | -33.981219 | 23.475540 | 1 | [-4.789999961853027, -4.260000228881836, -3.84... |
RH metrics
Let’s first split the rh variables into different columns. There are a total of 101 steps of percentiles defined starting from 0 to 100%.
# create rh metrics column
rh = []
# loop through each percentile and create a RH column
for i in range(101):
y = pd.DataFrame({f'RH{i}':subset_df['rh'].apply(lambda x: x[i])})
rh.append(y)
rh = pd.concat(rh, axis=1)
# concatenate RH columns to the original dataframe
subset_df = pd.concat([subset_df, rh], axis=1)
# print the first row of dataframe
subset_df.head(2)| delta_time | lat_lowestmode_a1 | lon_lowestmode_a1 | pft_class | lat_lowestmode | lon_lowestmode | quality_flag | rh | RH0 | RH1 | ... | RH91 | RH92 | RH93 | RH94 | RH95 | RH96 | RH97 | RH98 | RH99 | RH100 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4.764720e+07 | -33.980864 | 23.475097 | 2 | -33.980862 | 23.475095 | 1 | [-3.4000000953674316, -1.8300000429153442, -0.... | -3.40 | -1.83 | ... | 14.30 | 14.53 | 14.79 | 15.09 | 15.43 | 15.87 | 16.360001 | 16.959999 | 17.790001 | 18.870001 |
| 1 | 4.764720e+07 | -33.981219 | 23.475540 | 2 | -33.981219 | 23.475540 | 1 | [-4.789999961853027, -4.260000228881836, -3.84... | -4.79 | -4.26 | ... | 1.91 | 2.02 | 2.09 | 2.20 | 2.35 | 2.50 | 2.690000 | 2.920000 | 3.250000 | 3.960000 |
2 rows × 109 columns
gedi_gdf = gpd.GeoDataFrame(subset_df,
geometry=gpd.points_from_xy(subset_df.lon_lowestmode,
subset_df.lat_lowestmode),
crs="EPSG:4326")
gedi_sub = gpd.sjoin(gedi_gdf, poly, predicate='within')
gedi_sub[gedi_sub.quality_flag==1].explore("RH100", cmap = "YlGn", tiles=xyz, attr=attr, alpha=0.5, radius=10, legend=True)Make this Notebook Trusted to load map: File -> Trust Notebook
fig, ax = plt.subplots(figsize=(7, 10))
plot_df = gedi_sub[gedi_sub.quality_flag==1].filter(like='RH').T
plot_df.index = plot_df.index.str.strip('RH').astype(int)
plot_df.median(axis=1).plot(ax=ax, alpha=0.5, style='s:')
ax.set_xlabel("Percentile of waveform energy (%)")
ax.set_ylabel("Height (m)")
plt.show()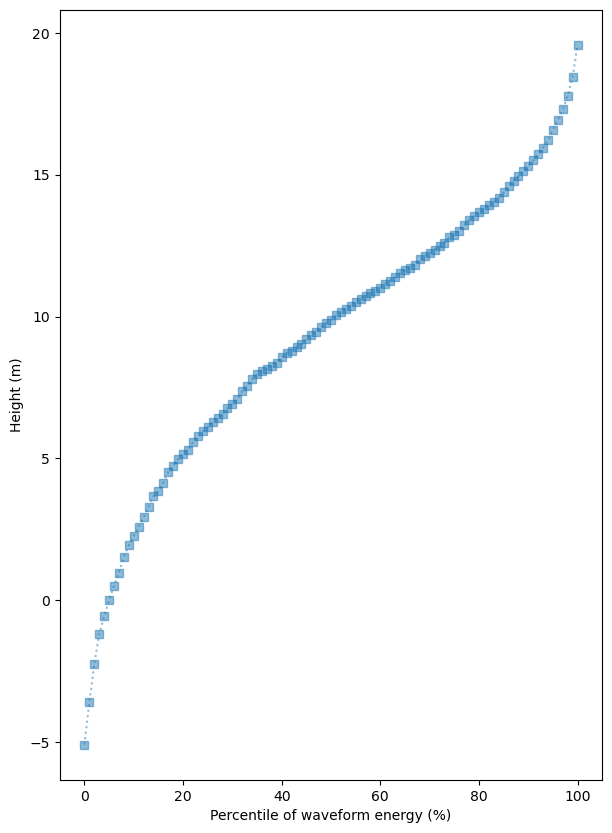
GEDI Waveform Structural Complexity Index (WSCI)
GEDI WSCI product (GEDI L4C) provides inference on forest structural complexity, which affects ecosystem functions, nutrient cycling, biodiversity, and habitat quality (Tiago et al. 2024)
concept_l4c = get_concept_id('10.3334/ORNLDAAC/2338') # GEDI L4C DOI
# harmony collection
collection_l4c = Collection(id=concept_l4c)
# gedi variables
variables_l4c = create_var_names(['wsci', 'wsci_quality_flag'])
# define an empty pandas dataframe
subset_df2 = pd.DataFrame()
# submit harmony
results2 = submit_harmony(collection_l4c, variables_l4c)
# loop through the Harmony results
for s3_url in results2:
print(s3_url)
with fs_s3.open(s3_url, mode='rb') as fh:
with h5py.File(fh) as l4c_in:
for v in list(l4c_in.keys()):
if v.startswith('BEAM'):
c_n, c_v = read_gedi_vars(l4c_in[v])
# Appending to the subset_df dataframe
subset_df2 = pd.concat([subset_df2,
pd.DataFrame(map(list, zip(*c_v)),
columns=c_n)]) [ Processing: 100% ] |###################################################| [|]s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838575/GEDI04_C_2022303102350_O21984_04_T08954_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838568/GEDI04_C_2021076044301_O12802_04_T10530_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838560/GEDI04_C_2019120211737_O02159_01_T02319_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838566/GEDI04_C_2020249085848_O09813_04_T10530_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838574/GEDI04_C_2022278051640_O21593_01_T10857_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838577/GEDI04_C_2022347020044_O22661_01_T05165_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838578/GEDI04_C_2023043015154_O23607_01_T02319_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838567/GEDI04_C_2021072061540_O12741_04_T07684_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838573/GEDI04_C_2022269000101_O21450_04_T04838_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838564/GEDI04_C_2020029234554_O06412_04_T04838_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838576/GEDI04_C_2022333221837_O22457_04_T10530_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838563/GEDI04_C_2019295150627_O04871_04_T01992_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838561/GEDI04_C_2019167025613_O02877_01_T05165_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838565/GEDI04_C_2020096211823_O07449_04_T01992_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838572/GEDI04_C_2022129160710_O19289_01_T09281_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838571/GEDI04_C_2022052222802_O18099_01_T10857_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838569/GEDI04_C_2021172232047_O14302_01_T08011_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838570/GEDI04_C_2021342191800_O16934_04_T07684_02_001_01_V002_subsetted.h5
s3://harmony-prod-staging/public/59c9676b-f302-4726-9d35-479f11c469fd/89838562/GEDI04_C_2019187095905_O03192_04_T04838_02_001_01_V002_subsetted.h5Now, let’s plot wsci variable for the good quality shots, which provides predicted 3D canopy entropy from the corresponding plant functional type or PFT (PFT=2 in this case).
# remove duplicate columns
subset_df2 = subset_df2.loc[:,~subset_df2.columns.duplicated()].copy()
gedi_gdf2 = gpd.GeoDataFrame(subset_df2,
geometry=gpd.points_from_xy(subset_df2.lon_lowestmode,
subset_df2.lat_lowestmode),
crs="EPSG:4326")
gedi_sub2 = gpd.sjoin(gedi_gdf2, poly, predicate='within')
gedi_sub2[gedi_sub2.wsci_quality_flag==1].explore("wsci", cmap = "YlGn", tiles=xyz, attr=attr,
alpha=0.5, radius=10, legend=True)Make this Notebook Trusted to load map: File -> Trust Notebook