import os
from datetime import datetime
import requests as r
import numpy as np
import pandas as pd
import geopandas as gp
from skimage import io
import matplotlib.pyplot as plt
from osgeo import gdal
import rasterio as rio
import xarray as xr
import rioxarray as rxr
import hvplot.xarray
import hvplot.pandas
import json
import panel as pn
import geoviews
import earthaccess
from pprint import pprintObserving Seasonality in Agricultural Areas
Overview
This tutorial was developed to examine changes in enhanced vegetation index (EVI) over an agricultural region in northern California. The goal of the project is to observe HLS-derived mean EVI over these regions without downloading the entirety of the HLS source data. In this notebook we will extract an EVI timeseries from Harmonized Landsat Sentinel-2 (HLS) data in the Cloud using the earthaccess and rioxarray libraries. This tutorial will show how to find the HLS data available in the cloud for our specific time period, bands (layers), and region of interest. After finding the desired data, we will load subsets of the cloud optimized geotiffs (COGs) into a Jupyter Notebook directly from the cloud, and calculate EVI. After calculating EVI we will save and stack the time series, visualize it, and export a CSV of EVI statistics for the region.
The Harmonized Landsat Sentinel-2 (HLS) project produces seamless, harmonized surface reflectance data from the Operational Land Imager (OLI) and Multi-Spectral Instrument (MSI) aboard Landsat and Sentinel-2 Earth-observing satellites, respectively. The aim is to produce seamless products with normalized parameters, which include atmospheric correction, cloud and cloud-shadow masking, geographic co-registration and common gridding, normalized bidirectional reflectance distribution function, and spectral band adjustment. This will provide global observation of the Earth’s surface every 2-3 days with 30 meter spatial resolution. One of the major applications that will benefit from HLS is agriculture assessment and monitoring, which is used as the use case for this tutorial.
NASA’s Land Processes Distributed Active Archive Center (LP DAAC) archives and distributes HLS products in the LP DAAC Cumulus cloud archive as Cloud Optimized GeoTIFFs (COG). This tutorial will demonstrate Because these data are stored as COGs, this tutorial will teach users how to load subsets of individual files into memory for just the bands you are interested in–a paradigm shift from the more common workflow where you would need to download a .zip/HDF file containing every band over the entire scene/tile. This tutorial covers how to process HLS data (calculate EVI), visualize, and “stack” the scenes over a region of interest into an xarray data array, calculate statistics for an EVI time series, and export as a comma-separated values (CSV) file–providing you with all of the information you need for your area of interest without having to download the source data file. The Enhanced Vegetation Index (EVI), is a vegetation index similar to NDVI that has been found to be more sensitive to ground cover below the vegetated canopy and saturates less over areas of dense green vegetation.
Requirements
A NASA Earthdata Login account is required to download the data used in this tutorial. You can create an account at the link provided.
You will will also need to have a netrc file set up in your home directory in order to successfully run the code below. A code chunk in a later section provides a way to do this, or you can check out the setup_intstructions.md.
Learning Objectives
- How to work with HLS Landsat (HLSL30.002) and Sentinel-2 (HLSS30.002) data products
- How to query and subset HLS data using the
earthaccesslibrary
- How to access and work with HLS data
Data Used
- Daily 30 meter (m) global HLS Sentinel-2 Multi-spectral Instrument Surface Reflectance - HLSS30.002
- The HLSS30 product provides 30 m Nadir normalized Bidirectional Reflectance Distribution Function (BRDF)-Adjusted Reflectance (NBAR) and is derived from Sentinel-2A and Sentinel-2B MSI data products.
- Science Dataset (SDS) layers:
- B8A (NIR Narrow)
- B04 (Red)
- B02 (Blue)
- Fmask (Quality)
- B8A (NIR Narrow)
- The HLSS30 product provides 30 m Nadir normalized Bidirectional Reflectance Distribution Function (BRDF)-Adjusted Reflectance (NBAR) and is derived from Sentinel-2A and Sentinel-2B MSI data products.
- Daily 30 meter (m) global HLS Landsat-8 OLI Surface Reflectance - HLSL30.002
- The HLSL30 product provides 30 m Nadir normalized Bidirectional Reflectance Distribution Function (BRDF)-Adjusted Reflectance (NBAR) and is derived from Landsat-8 OLI data products.
- Science Dataset (SDS) layers:
- B05 (NIR)
- B04 (Red)
- B02 (Blue)
- Fmask (Quality)
- B05 (NIR)
- The HLSL30 product provides 30 m Nadir normalized Bidirectional Reflectance Distribution Function (BRDF)-Adjusted Reflectance (NBAR) and is derived from Landsat-8 OLI data products.
Tutorial Outline
- Getting Started
1.1 Import Packages
1.2 EarthData Login
- Finding HLS Data
- Accessing HLS Cloud Optimized GeoTIFFs (COGs) from Earthdata Cloud 3.1 Subset by Band
3.2 Load COGS into Memory
3.3 Subset Spatially
3.4 Apply Scale Factor
- Processing HLS Data
4.1 Calculate EVI
4.2 Export to COG
- Automation
- Stacking HLS Data
6.1 Open and Stack COGs
6.2 Visualize Stacked Time Series
- Export Statistics
1. Getting Started
1.1 Import Packages
Import the required packages.
1.2 Earthdata Login Authentication
We will use the earthaccess package for authentication. earthaccess can either createa a new local .netrc file to store credentials or validate that one exists already in you user profile. If you do not have a .netrc file, you will be prompted for your credentials and one will be created.
auth = earthaccess.login()You're now authenticated with NASA Earthdata Login
Using token with expiration date: 11/06/2023
Using .netrc file for EDL2. Finding HLS Data using earthaccess
To find HLS data, we will use the earthaccess python library to search NASA’s Common Metadata Repository (CMR) for HLS data. We will use an geojson file containing our region of interest (ROI) to search for files that intersect. To do this, we will simplify it to a bounding box. Grab the bounding coordinates from the geopandas object after opening.
First we will read in our geojson file using geopandas
field = gp.read_file('https://git.earthdata.nasa.gov/projects/LPDUR/repos/hls-tutorial/raw/Field_Boundary.geojson?at=refs%2Fheads%2Fmain')We will use the total_bounds property to get the bounding box of our ROI, and add that to a python tuple, which is the expected data type for the bounding_box parameter earthaccess search_data.
bbox = tuple(list(field.total_bounds))
bbox(-122.0622682571411, 39.897234301806, -122.04918980598451, 39.91309383703065)When searching we can also search a specific time period of interest. Here we search from the beginning of May 2021 to the end of September 2021.
temporal = ("2021-05-01T00:00:00", "2021-09-30T23:59:59")Since the HLS collection contains to products, i.e. HLSL30 and HLSS30, we will include both short names. Search using our constraints and the count = 100 to limit our search to 100 results.
results = earthaccess.search_data(
short_name=['HLSL30','HLSS30'],
bounding_box=bbox,
temporal=temporal, # 2021-07-15T00:00:00Z/2021-09-15T23:59:59Z
count=100
)Granules found: 78We can preview these results in a pandas dataframe we want to check the metadata. Note we only show the first 5.
pd.json_normalize(results).head(5)| size | meta.concept-type | meta.concept-id | meta.revision-id | meta.native-id | meta.provider-id | meta.format | meta.revision-date | umm.TemporalExtent.RangeDateTime.BeginningDateTime | umm.TemporalExtent.RangeDateTime.EndingDateTime | ... | umm.CollectionReference.EntryTitle | umm.RelatedUrls | umm.DataGranule.DayNightFlag | umm.DataGranule.Identifiers | umm.DataGranule.ProductionDateTime | umm.DataGranule.ArchiveAndDistributionInformation | umm.Platforms | umm.MetadataSpecification.URL | umm.MetadataSpecification.Name | umm.MetadataSpecification.Version | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 198.882758 | granule | G2153255128-LPCLOUD | 1 | HLS.S30.T10TEK.2021122T185911.v2.0 | LPCLOUD | application/echo10+xml | 2021-10-29T10:47:01.310Z | 2021-05-02T19:13:19.930Z | 2021-05-02T19:13:19.930Z | ... | HLS Sentinel-2 Multi-spectral Instrument Surfa... | [{'URL': 'https://data.lpdaac.earthdatacloud.n... | Day | [{'Identifier': 'HLS.S30.T10TEK.2021122T185911... | 2021-10-29T10:44:28.000Z | [{'Name': 'Not provided', 'SizeInBytes': 20854... | [{'ShortName': 'Sentinel-2A', 'Instruments': [... | https://cdn.earthdata.nasa.gov/umm/granule/v1.6.5 | UMM-G | 1.6.5 |
| 1 | 186.999763 | granule | G2153407526-LPCLOUD | 1 | HLS.S30.T10TEK.2021124T184919.v2.0 | LPCLOUD | application/echo10+xml | 2021-10-29T14:09:37.033Z | 2021-05-04T19:03:22.997Z | 2021-05-04T19:03:22.997Z | ... | HLS Sentinel-2 Multi-spectral Instrument Surfa... | [{'URL': 'https://data.lpdaac.earthdatacloud.n... | Day | [{'Identifier': 'HLS.S30.T10TEK.2021124T184919... | 2021-10-29T13:51:48.000Z | [{'Name': 'Not provided', 'SizeInBytes': 19608... | [{'ShortName': 'Sentinel-2B', 'Instruments': [... | https://cdn.earthdata.nasa.gov/umm/granule/v1.6.5 | UMM-G | 1.6.5 |
| 2 | 199.237585 | granule | G2153881444-LPCLOUD | 1 | HLS.S30.T10TEK.2021127T185919.v2.0 | LPCLOUD | application/echo10+xml | 2021-10-30T00:59:05.213Z | 2021-05-07T19:13:19.594Z | 2021-05-07T19:13:19.594Z | ... | HLS Sentinel-2 Multi-spectral Instrument Surfa... | [{'URL': 'https://data.lpdaac.earthdatacloud.n... | Day | [{'Identifier': 'HLS.S30.T10TEK.2021127T185919... | 2021-10-29T21:47:54.000Z | [{'Name': 'Not provided', 'SizeInBytes': 20891... | [{'ShortName': 'Sentinel-2B', 'Instruments': [... | https://cdn.earthdata.nasa.gov/umm/granule/v1.6.5 | UMM-G | 1.6.5 |
| 3 | 102.786560 | granule | G2144019307-LPCLOUD | 1 | HLS.L30.T10TEK.2021128T184447.v2.0 | LPCLOUD | application/echo10+xml | 2021-10-15T03:48:08.875Z | 2021-05-08T18:44:47.423Z | 2021-05-08T18:45:11.310Z | ... | HLS Landsat Operational Land Imager Surface Re... | [{'URL': 'https://data.lpdaac.earthdatacloud.n... | Day | [{'Identifier': 'HLS.L30.T10TEK.2021128T184447... | 2021-10-14T22:05:21.000Z | [{'Name': 'Not provided', 'SizeInBytes': 10777... | [{'ShortName': 'LANDSAT-8', 'Instruments': [{'... | https://cdn.earthdata.nasa.gov/umm/granule/v1.6.5 | UMM-G | 1.6.5 |
| 4 | 186.955010 | granule | G2153591767-LPCLOUD | 1 | HLS.S30.T10TEK.2021129T184921.v2.0 | LPCLOUD | application/echo10+xml | 2021-10-29T16:27:32.621Z | 2021-05-09T19:03:25.151Z | 2021-05-09T19:03:25.151Z | ... | HLS Sentinel-2 Multi-spectral Instrument Surfa... | [{'URL': 'https://data.lpdaac.earthdatacloud.n... | Day | [{'Identifier': 'HLS.S30.T10TEK.2021129T184921... | 2021-10-29T16:13:58.000Z | [{'Name': 'Not provided', 'SizeInBytes': 19603... | [{'ShortName': 'Sentinel-2A', 'Instruments': [... | https://cdn.earthdata.nasa.gov/umm/granule/v1.6.5 | UMM-G | 1.6.5 |
5 rows × 24 columns
We can also preview each individual results by selecting it from the list. This will show the data links, and a browse image.
results[0]Data: HLS.S30.T10TEK.2021122T185911.v2.0.B10.tifHLS.S30.T10TEK.2021122T185911.v2.0.SZA.tifHLS.S30.T10TEK.2021122T185911.v2.0.B05.tifHLS.S30.T10TEK.2021122T185911.v2.0.VAA.tifHLS.S30.T10TEK.2021122T185911.v2.0.B04.tifHLS.S30.T10TEK.2021122T185911.v2.0.B01.tifHLS.S30.T10TEK.2021122T185911.v2.0.B07.tifHLS.S30.T10TEK.2021122T185911.v2.0.B02.tifHLS.S30.T10TEK.2021122T185911.v2.0.B08.tifHLS.S30.T10TEK.2021122T185911.v2.0.VZA.tifHLS.S30.T10TEK.2021122T185911.v2.0.B03.tifHLS.S30.T10TEK.2021122T185911.v2.0.B09.tifHLS.S30.T10TEK.2021122T185911.v2.0.B11.tifHLS.S30.T10TEK.2021122T185911.v2.0.B06.tifHLS.S30.T10TEK.2021122T185911.v2.0.B8A.tifHLS.S30.T10TEK.2021122T185911.v2.0.Fmask.tifHLS.S30.T10TEK.2021122T185911.v2.0.SAA.tifHLS.S30.T10TEK.2021122T185911.v2.0.B12.tif
Size: 198.88 MB
Cloud Hosted: True
We can grab all of the URLs for the data using list comprehension.
hls_results_urls = [granule.data_links() for granule in results]
print(f"There are {len(hls_results_urls)} granules and each granule contains {len(hls_results_urls[0])} assets. Below is an example of the assets printed for one granule:")
pprint(hls_results_urls[0])There are 78 granules and each granule contains 18 assets. Below is an example of the assets printed for one granule:
['https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.B10.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.SZA.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.B05.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.VAA.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.B04.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.B01.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.B07.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.B02.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.B08.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.VZA.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.B03.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.B09.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.B11.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.B06.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.B8A.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.Fmask.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.SAA.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.B12.tif']We can get the URLs for the browse images as well.
browse_urls = [granule.dataviz_links()[0] for granule in results] # 0 retrieves only the https links
pprint(browse_urls[0:5]) # Print the first five results['https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-public/HLSS30.020/HLS.S30.T10TEK.2021122T185911.v2.0/HLS.S30.T10TEK.2021122T185911.v2.0.jpg',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-public/HLSS30.020/HLS.S30.T10TEK.2021124T184919.v2.0/HLS.S30.T10TEK.2021124T184919.v2.0.jpg',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-public/HLSS30.020/HLS.S30.T10TEK.2021127T185919.v2.0/HLS.S30.T10TEK.2021127T185919.v2.0.jpg',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-public/HLSL30.020/HLS.L30.T10TEK.2021128T184447.v2.0/HLS.L30.T10TEK.2021128T184447.v2.0.jpg',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-public/HLSS30.020/HLS.S30.T10TEK.2021129T184921.v2.0/HLS.S30.T10TEK.2021129T184921.v2.0.jpg']3. Accessing HLS Cloud Optimized GeoTIFFs (COGs) from Earthdata Cloud
Now that we have a list of data URLs, we will configure gdal and rioxarray to access the cloud assets that we are interested in, and read them directly into memory without needing to download the files.
The Python libraries used to access COG files in Earthdata Cloud leverage GDAL’s virtual file systems. Whether you are running this code in the Cloud or in a local workspace, GDAL configurations must be set in order to successfully access the HLS COG files.
# GDAL configurations used to successfully access LP DAAC Cloud Assets via vsicurl
gdal.SetConfigOption('GDAL_HTTP_COOKIEFILE','~/cookies.txt')
gdal.SetConfigOption('GDAL_HTTP_COOKIEJAR', '~/cookies.txt')
gdal.SetConfigOption('GDAL_DISABLE_READDIR_ON_OPEN','EMPTY_DIR')
gdal.SetConfigOption('CPL_VSIL_CURL_ALLOWED_EXTENSIONS','TIF')
gdal.SetConfigOption('GDAL_HTTP_UNSAFESSL', 'YES')3.1 Subset by Band
Lets take a look at the URLs for one of our returned granules.
h = hls_results_urls[10]
h['https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B12.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B10.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B01.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.Fmask.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B04.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B8A.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B09.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B11.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.VAA.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B08.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.SZA.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B07.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B06.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B02.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.VZA.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B03.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B05.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.SAA.tif']To calculate the EVI for each granule we need the near-infrared, red, and blue bands. Below you can find the different band numbers for each of the two products.
Sentinel 2:
- "narrow" NIR = B8A
- Red = B04
- Blue = B02
- Quality = FmaskLandsat 8:
- NIR = B05
- Red = B04
- Blue = B02
- Quality = FmaskWe will subset our URLs to include the bands identified above in addition to the quality layer (Fmask).
evi_band_links = []
# Define which HLS product is being accessed
if h[0].split('/')[4] == 'HLSS30.020':
evi_bands = ['B8A', 'B04', 'B02', 'Fmask'] # NIR RED BLUE Quality for S30
else:
evi_bands = ['B05', 'B04', 'B02', 'Fmask'] # NIR RED BLUE Quality for L30
# Subset the assets in the item down to only the desired bands
for a in h:
if any(b in a for b in evi_bands):
evi_band_links.append(a)
evi_band_links['https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.Fmask.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B04.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B8A.tif',
'https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B02.tif']Remember from above that you can always quickly load in the browse image to get a quick view of the item using our list of browse URLs.
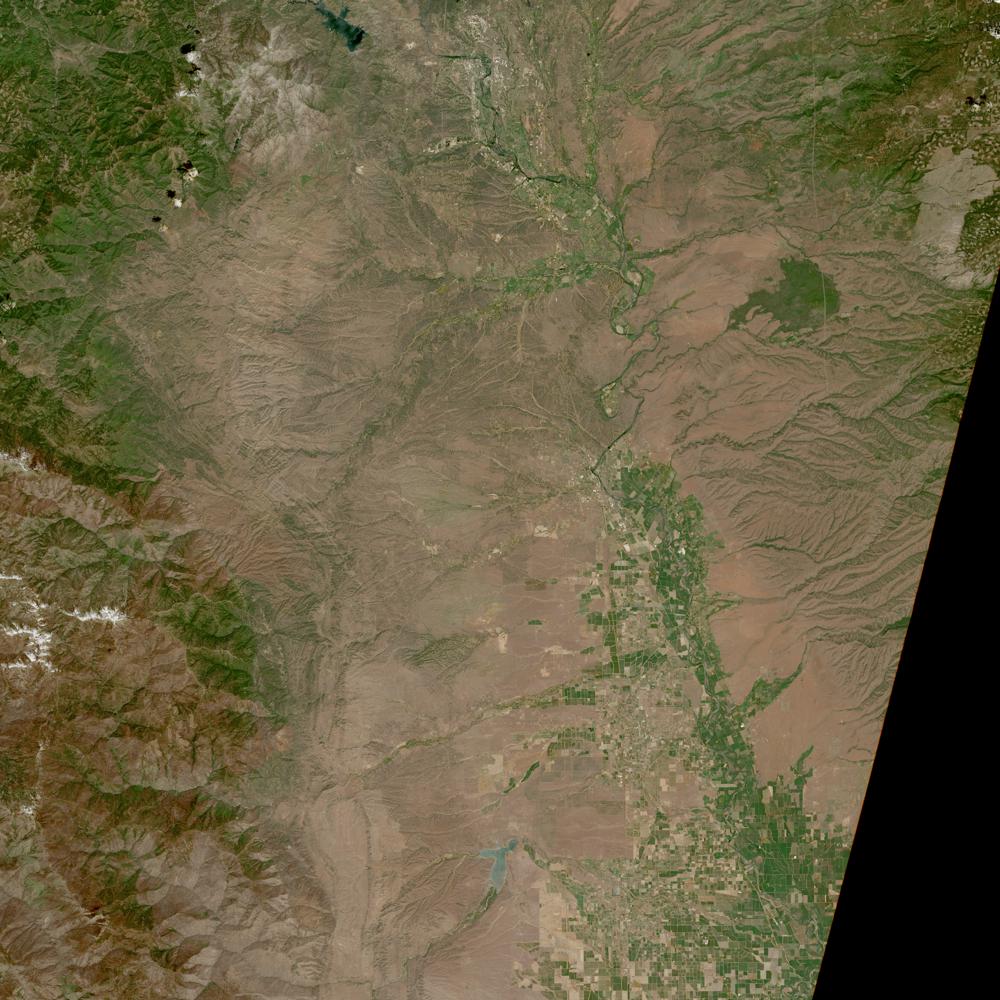
image = io.imread(browse_urls[10]) # Load jpg browse image into memory
# Basic plot of the image
plt.figure(figsize=(10,10))
plt.imshow(image)
plt.show()
Above, we see our first observation over the northern Central Valley of California.
del image # Remove the browse image3.2 Load HLS COGs into Memory
HLS COGs are broken into chunks allowing data to be read more efficiently. Define the chunk size of an HLS tile, mask the NaN values, then read the files using rioxarray and name them based upon the band. We also squeeze the object to remove the band dimension from most of the files, since there is only 1 band.
NOTE: To scale the bands, you can set the
mask_and_scaletoTrue(mask_and_scale=True), however thescale_factorinformation in some of the HLSL30 granules are found in thefilemetadata, but missing from theBandmetadata.rioxarraylooks for thescale_factorunderBandmetadata and if this information is missing it assumes thescale_factoris equal to 1. This results in having data to be uscaled and not masked for those granules. That is why we treat our data a bit differently here, leaving it unscaled and manually updating thescale_factorattribute in thexarraydataarray.
# Use vsicurl to load the data directly into memory (be patient, may take a few seconds)
chunk_size = dict(band=1, x=512, y=512) # Tiles have 1 band and are divided into 512x512 pixel chunks
for e in evi_band_links:
print(e)
if e.rsplit('.', 2)[-2] == evi_bands[0]: # NIR index
nir = rxr.open_rasterio(e, chunks=chunk_size, masked=True).squeeze('band', drop=True)
nir.attrs['scale_factor'] = 0.0001 # hard coded the scale_factor attribute
elif e.rsplit('.', 2)[-2] == evi_bands[1]: # red index
red = rxr.open_rasterio(e, chunks=chunk_size, masked=True).squeeze('band', drop=True)
red.attrs['scale_factor'] = 0.0001 # hard coded the scale_factor attribute
elif e.rsplit('.', 2)[-2] == evi_bands[2]: # blue index
blue = rxr.open_rasterio(e, chunks=chunk_size, masked=True).squeeze('band', drop=True)
blue.attrs['scale_factor'] = 0.0001 # hard coded the scale_factor attribute
# elif e.rsplit('.', 2)[-2] == evi_bands[3]: # Fmask index
# fmask = rxr.open_rasterio(e, chunks=chunk_size, masked=True).astype('uint16').squeeze('band', drop=True)
print("The COGs have been loaded into memory!")https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.Fmask.tif
https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B04.tif
https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B8A.tif
https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.B02.tif
The COGs have been loaded into memory!rxr.open_rasterio('https://data.lpdaac.earthdatacloud.nasa.gov/lp-prod-protected/HLSS30.020/HLS.S30.T10TEK.2021142T185921.v2.0/HLS.S30.T10TEK.2021142T185921.v2.0.Fmask.tif')<xarray.DataArray (band: 1, y: 3660, x: 3660)>
[13395600 values with dtype=uint8]
Coordinates:
* band (band) int32 1
* x (x) float64 5e+05 5e+05 5.001e+05 ... 6.097e+05 6.098e+05
* y (y) float64 4.5e+06 4.5e+06 4.5e+06 ... 4.39e+06 4.39e+06
spatial_ref int32 0
Attributes: (12/42)
ACCODE: LaSRC
AREA_OR_POINT: Area
arop_ave_xshift(meters): 0
arop_ave_yshift(meters): 0
arop_ncp: 0
arop_rmse(meters): 0
... ...
TILE_ID: S2A_OPER_MSI_L1C_TL_VG...
ULX: 499980
ULY: 4500000
_FillValue: 255
scale_factor: 1.0
add_offset: 0.0NOTE: Getting an error in the section above? Accessing these files in the cloud requires you to authenticate using your NASA Earthdata Login account. You will need to have a netrc file set up containing those credentials in your home directory in order to successfully run the code below. Please make sure you have a valid username and password in the created netrc file.
We can take a quick look at one of the dataarray we just read in.
nir<xarray.DataArray (y: 3660, x: 3660)>
dask.array<getitem, shape=(3660, 3660), dtype=float32, chunksize=(512, 512), chunktype=numpy.ndarray>
Coordinates:
* x (x) float64 5e+05 5e+05 5.001e+05 ... 6.097e+05 6.098e+05
* y (y) float64 4.5e+06 4.5e+06 4.5e+06 ... 4.39e+06 4.39e+06
spatial_ref int32 0
Attributes: (12/41)
ACCODE: LaSRC
add_offset: 0.0
AREA_OR_POINT: Area
arop_ave_xshift(meters): 0
arop_ave_yshift(meters): 0
arop_ncp: 0
... ...
SPACECRAFT_NAME: Sentinel-2A
spatial_coverage: 92
SPATIAL_RESOLUTION: 30
TILE_ID: S2A_OPER_MSI_L1C_TL_VG...
ULX: 499980
ULY: 4500000
Note the full size of the array, y=3660 & x=3660
3.3 Subset spatially
Before we can subset using our input farm field, we will first need to convert the geopandas dataframe from lat/lon (EPSG: 4326) into the projection used by HLS, UTM (aligned to the Military Grid Reference System). Since UTM is a zonal projection, we’ll need to extract the unique UTM zonal projection parameters from our input HLS files and use them to transform the coordinate of our input farm field.
We can print out the WKT string for our HLS tiles.
nir.spatial_ref.crs_wkt'PROJCS["UTM Zone 10, Northern Hemisphere",GEOGCS["Unknown datum based upon the WGS 84 ellipsoid",DATUM["Not specified (based on WGS 84 spheroid)",SPHEROID["WGS 84",6378137,298.257223563,AUTHORITY["EPSG","7030"]]],PRIMEM["Greenwich",0],UNIT["degree",0.0174532925199433,AUTHORITY["EPSG","9122"]]],PROJECTION["Transverse_Mercator"],PARAMETER["latitude_of_origin",0],PARAMETER["central_meridian",-123],PARAMETER["scale_factor",0.9996],PARAMETER["false_easting",500000],PARAMETER["false_northing",0],UNIT["metre",1,AUTHORITY["EPSG","9001"]],AXIS["Easting",EAST],AXIS["Northing",NORTH]]'We will use this information to transform the coordinates of our ROI to the proper UTM projection.
fsUTM = field.to_crs(nir.spatial_ref.crs_wkt) # Take the CRS from the NIR tile that we opened and apply it to our field geodataframe.
fsUTM| geometry | |
|---|---|
| 0 | POLYGON ((581047.926 4418541.913, 580150.196 4... |
Now, we can use our field ROI to mask any pixels that fall outside of it and crop to the bounding box using rasterio. This greatly reduces the amount of data that are needed to load into memory.
nir_cropped = nir.rio.clip(fsUTM.geometry.values, fsUTM.crs, all_touched=True) # All touched includes any pixels touched by the polygon
nir_cropped<xarray.DataArray (y: 59, x: 38)>
dask.array<getitem, shape=(59, 38), dtype=float32, chunksize=(59, 38), chunktype=numpy.ndarray>
Coordinates:
* x (x) float64 5.802e+05 5.802e+05 ... 5.812e+05 5.813e+05
* y (y) float64 4.419e+06 4.419e+06 ... 4.417e+06 4.417e+06
spatial_ref int32 0
Attributes: (12/41)
ACCODE: LaSRC
add_offset: 0.0
AREA_OR_POINT: Area
arop_ave_xshift(meters): 0
arop_ave_yshift(meters): 0
arop_ncp: 0
... ...
SPACECRAFT_NAME: Sentinel-2A
spatial_coverage: 92
SPATIAL_RESOLUTION: 30
TILE_ID: S2A_OPER_MSI_L1C_TL_VG...
ULX: 499980
ULY: 4500000
Note that the array size is considerably smaller than the full size we read in before.
Now we will plot the cropped NIR data.
nir_cropped.hvplot.image(aspect='equal', cmap='viridis', frame_height=500, frame_width= 500).opts(title='HLS Cropped NIR Band') # Quick visual to assure that it workedAbove, you can see that the data have been loaded into memory already subset to our ROI. Also notice that the data has not been scaled (see the legend). We will next scaled the data using the function defined below.
3.4 Apply Scale Factor
# Define function to scale
def scaling(band):
scale_factor = band.attrs['scale_factor']
band_out = band.copy()
band_out.data = band.data*scale_factor
band_out.attrs['scale_factor'] = 1
return(band_out)nir_cropped_scaled = scaling(nir_cropped)We can plot to confirm our manual scaling worked.
nir_cropped_scaled.hvplot.image(aspect='equal', cmap='viridis', frame_height=500, frame_width= 500).opts(title='HLS Cropped NIR Band') # Quick visual to assure that it workedNext, load in the red and blue bands and fix their scaling as well.
# Red
red_cropped = red.rio.clip(fsUTM.geometry.values, fsUTM.crs, all_touched=True)
red_cropped_scaled = scaling(red_cropped)
# Blue
blue_cropped = blue.rio.clip(fsUTM.geometry.values, fsUTM.crs, all_touched=True)
blue_cropped_scaled = scaling(blue_cropped)
print('Data is loaded and scaled!')Data is loaded and scaled!4. Processing HLS Data
In this section we will use the HLS data we’ve access to calculate the EVI. We will do this by defining a function to calculate EVI that will retain the attributes and metadata associated with the data we accessed.
4.1 Calculate EVI
Below is a function we will use to calculate EVI using the NIR, Red, and Blue bands. The function will build a new xarray dataarray with EVI values and copy the original file metadata to the new xarray dataarray
def calc_evi(red, blue, nir):
# Create EVI xarray.DataArray that has the same coordinates and metadata
evi = red.copy()
# Calculate the EVI
evi_data = 2.5 * ((nir.data - red.data) / (nir.data + 6.0 * red.data - 7.5 * blue.data + 1.0))
# Replace the Red xarray.DataArray data with the new EVI data
evi.data = evi_data
# exclude the inf values
evi = xr.where(evi != np.inf, evi, np.nan, keep_attrs=True)
# change the long_name in the attributes
evi.attrs['long_name'] = 'EVI'
evi.attrs['scale_factor'] = 1
return eviBelow, apply the EVI function on the scaled data.
evi_cropped = calc_evi(red_cropped_scaled, blue_cropped_scaled, nir_cropped_scaled) # Generate EVI array
evi_cropped<xarray.DataArray (y: 59, x: 38)>
dask.array<where, shape=(59, 38), dtype=float32, chunksize=(59, 38), chunktype=numpy.ndarray>
Coordinates:
* x (x) float64 5.802e+05 5.802e+05 ... 5.812e+05 5.813e+05
* y (y) float64 4.419e+06 4.419e+06 ... 4.417e+06 4.417e+06
spatial_ref int32 0
Attributes: (12/41)
ACCODE: LaSRC
add_offset: 0.0
AREA_OR_POINT: Area
arop_ave_xshift(meters): 0
arop_ave_yshift(meters): 0
arop_ncp: 0
... ...
SPACECRAFT_NAME: Sentinel-2A
spatial_coverage: 92
SPATIAL_RESOLUTION: 30
TILE_ID: S2A_OPER_MSI_L1C_TL_VG...
ULX: 499980
ULY: 4500000Next, plot the results using hvplot.
evi_cropped.hvplot.image(aspect='equal', cmap='YlGn', frame_height=500, frame_width= 500).opts(title=f'HLS-derived EVI, {evi_cropped.SENSING_TIME}', clabel='EVI')Above, notice that variation of green level appearing in different fields in our ROI, some being much greener than the others.
4.2. Export to COG
In this section, create an output filename and export the cropped EVI to COG.
original_name = evi_band_links[0].split('/')[-1]
original_name'HLS.S30.T10TEK.2021142T185921.v2.0.Fmask.tif'The standard format for HLS S30 V2.0 and HLS L30 V2.0 filenames is as follows: > HLS.S30/HLS.L30: Product Short Name
T10TEK: MGRS Tile ID (T+5-digits)
2020273T190109: Julian Date and Time of Acquisition (YYYYDDDTHHMMSS)
v2.0: Product Version
B8A/B05: Spectral Band
.tif: Data Format (Cloud Optimized GeoTIFF)
For additional information on HLS naming conventions, be sure to check out the HLS Overview Page.
Now modify the filename to describe that its EVI, cropped to an ROI.
out_name = f"{original_name.split('v2.0')[0]}v2.0_EVI_cropped.tif" # Generate output name from the original filename
out_name'HLS.S30.T10TEK.2021142T185921.v2.0_EVI_cropped.tif'Use the COG driver to write a local raster output. A cloud-optimized geotiff (COG) is a geotiff file that has been tiled and includes overviews so it can be accessed and previewed without having to load the entire image into memory at once.
out_folder = './data/'
if not os.path.exists(out_folder): os.makedirs(out_folder)
evi_cropped.rio.to_raster(raster_path=f'{out_folder}{out_name}', driver='COG')# del evi_cropped, out_folder, out_name, fmask_cropped, red_cropped, blue_cropped, nir_cropped, red_cropped_scaled, blue_cropped_scaled, nir_cropped_scaled5. Automation
In this section, automate sections 4-5 for each HLS item that intersects our spatiotemporal subset of interest. Loop through each item and subset to the desired bands, load the spatial subset into memory, apply the scale factor, calculate EVI, and export as a Cloud Optimized GeoTIFF.
len(hls_results_urls)78Now put it all together and loop through each of the files, visualize and export cropped EVI files. Be patient with the for loop below, it may take a few minutes to complete.
for j, h in enumerate(hls_results_urls):
outName = h[0].split('/')[-1].split('v2.0')[0] +'v2.0_EVI_cropped.tif'
#print(outName)
evi_band_links = []
if h[0].split('/')[4] == 'HLSS30.020':
evi_bands = ['B8A', 'B04', 'B02', 'Fmask'] # NIR RED BLUE FMASK
else:
evi_bands = ['B05', 'B04', 'B02', 'Fmask'] # NIR RED BLUE FMASK
for a in h:
if any(b in a for b in evi_bands):
evi_band_links.append(a)
# Check if file already exists in output directory, if yes--skip that file and move to the next observation
if os.path.exists(f'{out_folder}{outName}'):
print(f"{outName} has already been processed and is available in this directory, moving to next file.")
continue
# Use vsicurl to load the data directly into memory (be patient, may take a few seconds)
chunk_size = dict(band=1, x=512, y=512) # Tiles have 1 band and are divided into 512x512 pixel chunks
for e in evi_band_links:
#print(e)
if e.rsplit('.', 2)[-2] == evi_bands[0]: # NIR index
nir = rxr.open_rasterio(e, chunks=chunk_size, masked= True).squeeze('band', drop=True)
nir.attrs['scale_factor'] = 0.0001 # hard coded the scale_factor attribute
elif e.rsplit('.', 2)[-2] == evi_bands[1]: # red index
red = rxr.open_rasterio(e, chunks=chunk_size, masked= True).squeeze('band', drop=True)
red.attrs['scale_factor'] = 0.0001 # hard coded the scale_factor attribute
elif e.rsplit('.', 2)[-2] == evi_bands[2]: # blue index
blue = rxr.open_rasterio(e, chunks=chunk_size, masked= True).squeeze('band', drop=True)
blue.attrs['scale_factor'] = 0.0001 # hard coded the scale_factor attribute
elif e.rsplit('.', 2)[-2] == evi_bands[3]: # Fmask index
fmask = rxr.open_rasterio(e, chunks=chunk_size, masked= True).astype('uint16').squeeze('band', drop=True)
#print("The COGs have been loaded into memory!")
fsUTM = field.to_crs(nir.spatial_ref.crs_wkt)
# Crop to our ROI and apply scaling and masking
nir_cropped = nir.rio.clip(fsUTM.geometry.values, fsUTM.crs, all_touched=True)
red_cropped = red.rio.clip(fsUTM.geometry.values, fsUTM.crs, all_touched=True)
blue_cropped = blue.rio.clip(fsUTM.geometry.values, fsUTM.crs, all_touched=True)
fmask_cropped = fmask.rio.clip(fsUTM.geometry.values, fsUTM.crs, all_touched=True)
#print('Cropped')
# Fix Scaling
nir_cropped_scaled = scaling(nir_cropped)
red_cropped_scaled = scaling(red_cropped)
blue_cropped_scaled = scaling(blue_cropped)
# Generate EVI
evi_cropped = calc_evi(red_cropped_scaled, blue_cropped_scaled, nir_cropped_scaled)
#print('EVI Calculated')
# Remove any observations that are entirely fill value
if np.nansum(evi_cropped.data) == 0.0:
print(f"File: {h[0].split('/')[-1].rsplit('.', 1)[0]} was entirely fill values and will not be exported.")
continue
evi_cropped.rio.to_raster(raster_path=f'{out_folder}{outName}', driver='COG')
print(f"Processing file {j+1} of {len(hls_results_urls)}")
Processing file 1 of 78
Processing file 2 of 78
Processing file 3 of 78
Processing file 4 of 78
Processing file 5 of 78
Processing file 6 of 78
Processing file 7 of 78
Processing file 8 of 78
Processing file 9 of 78
Processing file 10 of 78
HLS.S30.T10TEK.2021142T185921.v2.0_EVI_cropped.tif has already been processed and is available in this directory, moving to next file.
Processing file 12 of 78
Processing file 13 of 78
Processing file 14 of 78
Processing file 15 of 78
Processing file 16 of 78
Processing file 17 of 78
Processing file 18 of 78
Processing file 19 of 78
Processing file 20 of 78
Processing file 21 of 78
Processing file 22 of 78
Processing file 23 of 78
Processing file 24 of 78
Processing file 25 of 78
Processing file 26 of 78
Processing file 27 of 78
Processing file 28 of 78
Processing file 29 of 78
Processing file 30 of 78
Processing file 31 of 78
Processing file 32 of 78
Processing file 33 of 78
Processing file 34 of 78
Processing file 35 of 78
Processing file 36 of 78
Processing file 37 of 78
Processing file 38 of 78
Processing file 39 of 78
Processing file 40 of 78
Processing file 41 of 78
Processing file 42 of 78
Processing file 43 of 78
Processing file 44 of 78
Processing file 45 of 78
Processing file 46 of 78
Processing file 47 of 78
Processing file 48 of 78
Processing file 49 of 78
Processing file 50 of 78
Processing file 51 of 78
Processing file 52 of 78
Processing file 53 of 78
Processing file 54 of 78
Processing file 55 of 78
Processing file 56 of 78
Processing file 57 of 78
Processing file 58 of 78
Processing file 59 of 78
Processing file 60 of 78
Processing file 61 of 78
Processing file 62 of 78
Processing file 63 of 78
Processing file 64 of 78
Processing file 65 of 78
Processing file 66 of 78
Processing file 67 of 78
Processing file 68 of 78
Processing file 69 of 78
Processing file 70 of 78
Processing file 71 of 78
Processing file 72 of 78
Processing file 73 of 78
Processing file 74 of 78
Processing file 75 of 78
Processing file 76 of 78
Processing file 77 of 78
Processing file 78 of 78Now there should be multiple COGs exported to your working directory, that will be used in Section 6 to stack into a time series.
6. Stacking HLS Data
In this section we will open multiple HLS-derived EVI COGs and stack them into an xarray data array along the time dimension. First list the files we created in the /data/ directory.
6.1 Open and Stack COGs
evi_files = [os.path.abspath(o) for o in os.listdir(out_folder) if o.endswith('EVI_cropped.tif')] # List EVI COGsCreate a time index as an xarray variable from the filenames.
def time_index_from_filenames(evi_files):
'''
Helper function to create a pandas DatetimeIndex
'''
return [datetime.strptime(f.split('.')[-4], '%Y%jT%H%M%S') for f in evi_files]
time = xr.Variable('time', time_index_from_filenames(evi_files))Next, the cropped HLS COG files are being read using rioxarray and a time series stack is created using xarray.
#evi_ts = evi_ts.squeeze('band', drop=True)
chunks=dict(band=1, x=512, y=512)
evi_ts = xr.concat([rxr.open_rasterio(f, mask_and_scale=True, chunks=chunks).squeeze('band', drop=True) for f in evi_files], dim=time)
evi_ts.name = 'EVI'evi_ts = evi_ts.sortby(evi_ts.time)
evi_ts<xarray.DataArray 'EVI' (time: 78, y: 59, x: 38)>
dask.array<getitem, shape=(78, 59, 38), dtype=float32, chunksize=(1, 59, 38), chunktype=numpy.ndarray>
Coordinates:
* x (x) float64 5.802e+05 5.802e+05 ... 5.812e+05 5.813e+05
* y (y) float64 4.419e+06 4.419e+06 ... 4.417e+06 4.417e+06
spatial_ref int32 0
* time (time) datetime64[ns] 2021-05-02T18:59:11 ... 2021-09-29T19:...
Attributes: (12/33)
ACCODE: Lasrc; Lasrc
AREA_OR_POINT: Area
arop_ave_xshift(meters): 0, 0
arop_ave_yshift(meters): 0, 0
arop_ncp: 0, 0
arop_rmse(meters): 0, 0
... ...
SPATIAL_RESOLUTION: 30
TIRS_SSM_MODEL: FINAL; FINAL
TIRS_SSM_POSITION_STATUS: ESTIMATED; ESTIMATED
ULX: 499980
ULY: 4500000
USGS_SOFTWARE: LPGS_15.4.0
6.2 Visualize Stacked Time Series
Below, use the hvPlot and holoviews packages to create an interactive time series plot of the HLS derived EVI data.Basemap layer is also added to provide better context of the areas surrounding our region of interest.
# This cell generates a warning
import warnings
warnings.filterwarnings('ignore')
# set the x, y, and z (groupby) dimensions, add a colormap/bar and other parameters.
title = 'HLS-derived EVI over agricultural fields in northern California'
evi_ts.hvplot.image(x='x', y='y', groupby = 'time', frame_height=500, frame_width= 500, cmap='YlGn', geo=True, tiles = 'EsriImagery',)Looking at the time series above, the farm fields are pretty stable in terms of EVI during our temporal range. The slow decrease in EVI as we move toward Fall season could show these fields are having some sort of trees rather than crops. I encourage you to expand your temporal range to learn more about the EVI annual and seasonal changes.
Since the data is in an xarray we can intuitively slice or reduce the dataset. Let’s select a single time slice from the EVI variable.
You can use slicing to plot data only for a specific observation, for example.
title = 'HLS-derived EVI over agricultural fields in northern California'
# evi_cropped.hvplot.image(aspect='equal', cmap='YlGn', frame_width=300).opts(title=f'HLS-derived EVI, {evi_cropped.SENSING_TIME}', clabel='EVI')
evi_ts.isel(time=1).hvplot.image(x='x', y='y', cmap='YlGn', geo=True, tiles = 'EsriImagery', frame_height=500, frame_width= 500).opts(title=f'{title}, {evi_ts.isel(time=4).SENSING_TIME}')Now, plot the time series as boxplots showing the distribution of EVI values for our farm field.
evi_ts.hvplot.box('EVI', by=['time'], rot=90, box_fill_color='lightblue', width=800, height=600).opts(ylim=(0,1.0))The statistics shows a relatively stable green status in these fields during mid May to the end of September 2021.
7. Export Statistics
Next, calculate statistics for each observation and export to CSV.
# xarray allows you to easily calculate a number of statistics
evi_min = evi_ts.min(('y', 'x'))
evi_max = evi_ts.max(('y', 'x'))
evi_mean = evi_ts.mean(('y', 'x'))
evi_sd = evi_ts.std(('y', 'x'))
evi_count = evi_ts.count(('y', 'x'))
evi_median = evi_ts.median(('y', 'x'))We now have the mean and standard deviation for each time slice as well as the maximum and minimum values. Let’s do some plotting! We will use the hvPlot package to create simple but interactive charts/plots. Hover your curser over the visualization to see the data values.
evi_mean.hvplot.line()# Ignore warnings
import warnings
warnings.filterwarnings('ignore')
# Combine line plots for different statistics
stats = (evi_mean.hvplot.line(height=350, width=450, line_width=1.5, color='red', grid=True, padding=0.05).opts(title='Mean')+
evi_sd.hvplot.line(height=350, width=450, line_width=1.5, color='red', grid=True, padding=0.05).opts(title='Standard Deviation')
+ evi_max.hvplot.line(height=350, width=450, line_width=1.5, color='red', grid=True, padding=0.05).opts(title='Max') +
evi_min.hvplot.line(height=350, width=450, line_width=1.5, color='red', grid=True, padding=0.05).opts(title='Min')).cols(2)
statsRemember that these graphs are also interactive–hover over the line to see the value for a given date.
Finally, create a pandas dataframe with the statistics, and export to a CSV file.
# Create pandas dataframe from dictionary
df = pd.DataFrame({'Min EVI': evi_min, 'Max EVI': evi_max,
'Mean EVI': evi_mean, 'Standard Deviation EVI': evi_sd,
'Median EVI': evi_median, 'Count': evi_count})df.index = evi_ts.time.data # Set the observation date as the index
df.to_csv(f'{out_folder}HLS-Derived_EVI_Stats.csv', index=True) # Unhash to export to CSVNow remove the output files to clean up the workspace.
import shutil
shutil.rmtree(os.path.abspath(out_folder)) # Execute once ready to remove output filesSuccess! You have now not only learned how to get started with HLS V2.0 data, but have also learned how to navigate cloud-native data using STAC, how to access subsets of COGs, and how to write COGs for your own outputs. Using this jupyter notebook as a workflow, you should now be able to switch to your specific region of interest and re-run the notebook. Good Luck!
Contact Info
Email: LPDAAC@usgs.gov
Voice: +1-866-573-3222
Organization: Land Processes Distributed Active Archive Center (LP DAAC)¹
Website: https://lpdaac.usgs.gov/
Date last modified: 09-08-2023
¹Work performed under USGS contract G15PD00467 for NASA contract NNG14HH33I.